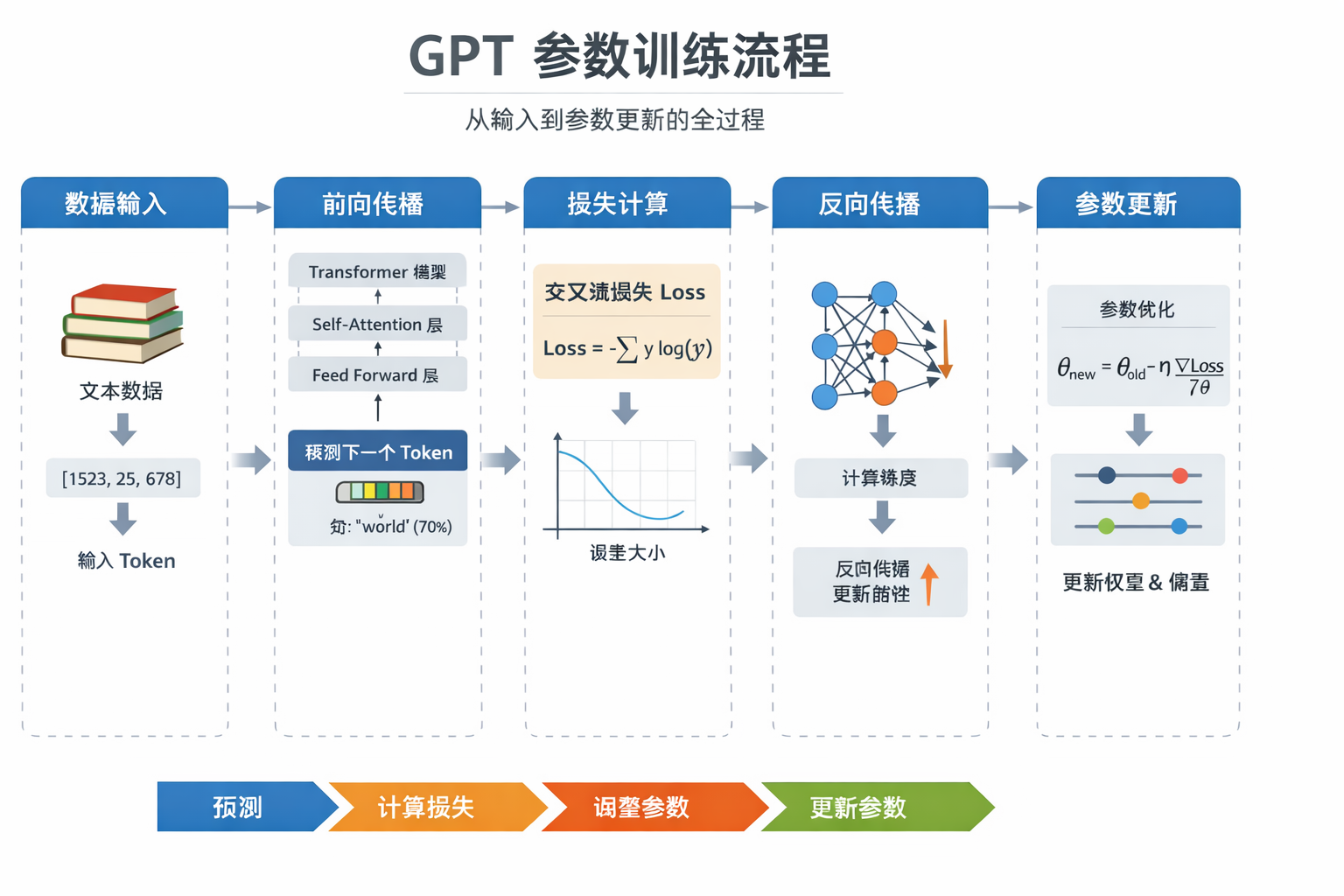
为什么GPT 参数越多能力越强,我会从数学原理+ 模型表现+ 直观类比三个角度讲。
一、参数多= 模型容量大
GPT 参数就是神经网络里的权重和偏置。
-
每个参数都相当于模型“记忆一点规律”的能力
-
参数越多→ 模型能“记住和组合”的模式越多
直观类比:
-
你写文章,如果你只有10 个单词可用→ 能写的句子非常有限
-
你有10 万个单词→ 可以组合出丰富多样、复杂的句子
-
GPT 参数多,就像词汇量和思维组合能力变大
二、数学上:函数逼近能力更强
GPT 可以看作一个函数逼近器:
和=f(x;我)y = f(x; θ)和=f ( x ;我)
-
我θ我= 参数
-
xxx= 输入
-
和和和= 输出概率分布(下一个token)
理论上:
参数越多,神经网络可以逼近任意复杂函数。
也就是说:
-
少量参数→ 模型只能学习简单语言规律
-
大量参数→ 模型可以学习复杂语法、长距离依赖、抽象语义、推理模式
三、处理上下文能力更强
-
Transformer 的Self-Attention 会计算token 之间的关系
-
参数越多→ 注意力机制的投影矩阵更丰富→ 可以捕捉更长、更复杂的上下文依赖
例如:
-
小模型可能只能处理50 个token 内的关系
-
大模型可以处理2,000+ token 内的复杂逻辑
-
所以大模型生成长文更连贯、逻辑更准确
四、知识存储能力更强
GPT 在训练过程中会“吸收知识模式”:
-
每个参数可以看作储存一小块语言/知识规律
-
参数越多→ 模型能记住更多事实、公式、单词用法、常识
-
所以大模型回答问题更准确、覆盖面更广
五、类比例子
-
小模型:像初中生,记住的词汇和逻辑有限
-
大模型:像博士生,记住的知识面广,推理能力强,能写长篇文章
-
超大模型:像百科全书+ 文学创作能力结合,既懂事实也懂语言模式
六、但参数多也有局限
-
成本高:训练、推理都需要更多GPU 和显存
-
并非总是正确:幻觉、错误信息不会自动减少
-
效率问题:推理慢,需要做蒸馏或剪枝优化
💡一句话总结:
GPT 参数越多→ 模型容量越大→ 能捕捉更复杂语言模式、长距离上下文、知识记忆和推理能力→ 生成文本更准确自然。
如果你愿意,我可以画一张参数数量vs 能力对比图,直观展示小模型、中模型、大模型的区别,让这个概念一眼就看懂。
你希望我画吗?