大型语言模型(Large Language Model, LLM) 是基于 Transformer 架构 构建的深度学习模型,专门用于理解和生成自然语言。它们通过在海量文本数据上训练,学会语言规律、语义关系和推理能力。

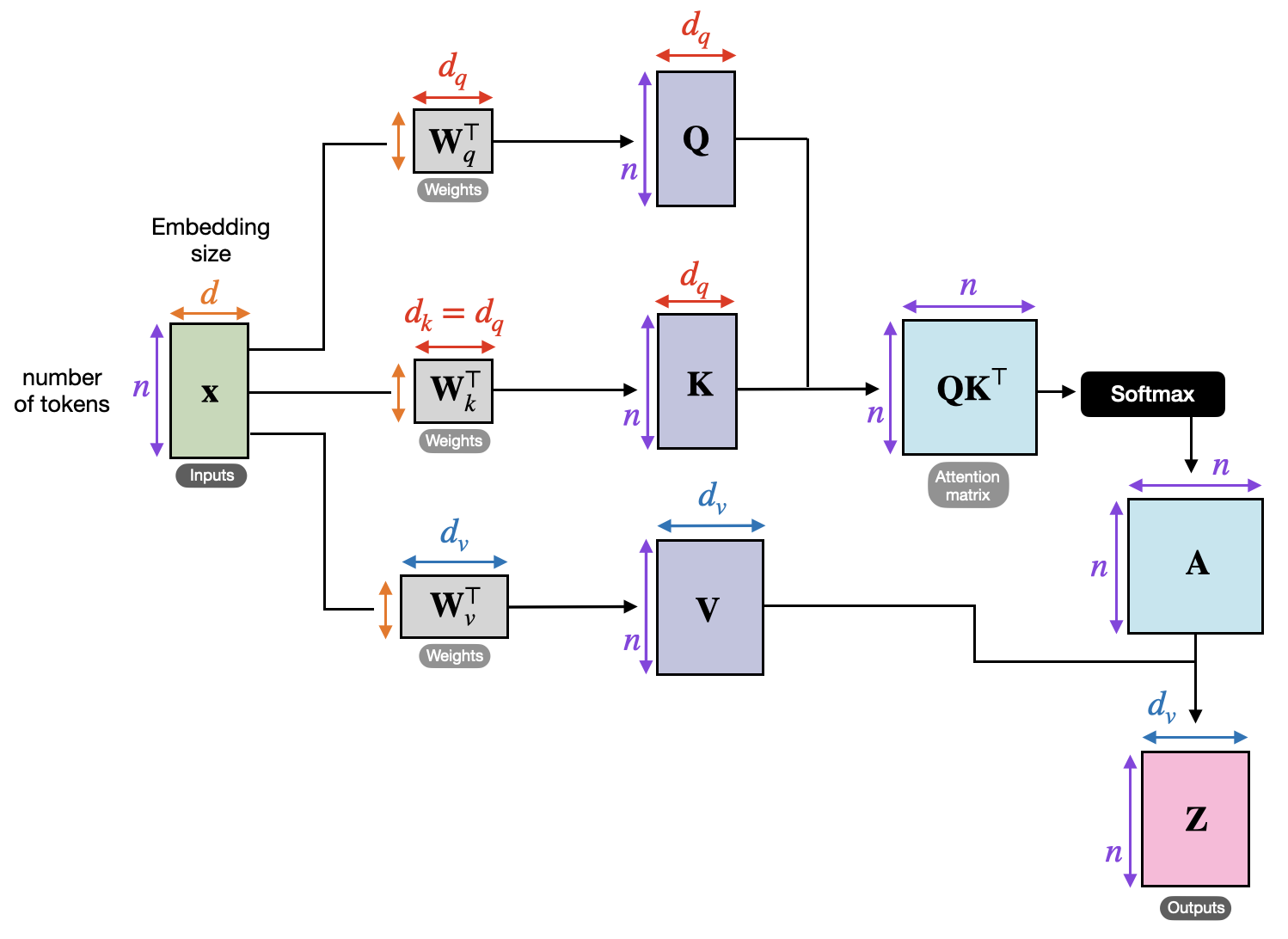

Transformer 由 Ashish Vaswani 等人在 2017 年论文
《Attention Is All You Need》 中提出。
模型在处理一个词时,会关注句子中的所有词
能捕捉长距离依赖关系
比 RNN / LSTM 更并行高效
同时从不同“角度”理解语义关系
提升表达能力
编码器:理解输入
解码器:生成输出
有些模型只用编码器或只用解码器
代表:Google 的 BERT
擅长文本理解
用于分类、问答、情感分析
代表:OpenAI 的 GPT
擅长文本生成
目前主流 LLM 多采用这种结构
代表:Google 的 T5
统一输入输出格式
适合翻译、摘要等任务
LLM 之所以“大”,体现在:
🔹 参数量巨大(几十亿到上万亿)
🔹 使用海量数据训练
🔹 借助 GPU / TPU 并行计算
例如:
GPT-3:1750 亿参数
GPT-4:规模更大(未公开)
模型规模越大:
表达能力越强
泛化能力更好
但计算成本更高
在海量文本上做自监督学习
目标:预测下一个词
用特定任务数据优化
或通过人类反馈强化学习(RLHF)
✅ 并行计算效率高
✅ 能处理长文本
✅ 可扩展性强
✅ 可迁移到多种任务
Transformer = “用注意力机制理解整个句子关系”
LLM = “在海量数据上训练的超大 Transformer”
如果你愿意,我可以继续深入讲:
数学层面的 Attention 公式
KV Cache 原理
为什么 Scaling Law 有效
或者推理阶段是怎么一步步生成文本的